日本語の文字化けを直そう

初めまして。タロスカイのマリアです。
今回の投稿は私の第一投稿です。宜しくお願い致します。
本日のテーマは文字コードにしたいと思いますね。実は現在日本の大学院に通っています。この間研究で文字コードの問題に遭い困っていたのですが解決できたので、みんなさんにシェアしたいと思います。もし参考になったら嬉しいです。
うちの研究室では自然言語処理に関連した研究をしています。実験を行うために、いわゆるコーパスという文章の膨大な集まりが使われてることが多いです。テンプレートにマッチする文章を検索する前に、ファイルの内容を確認しないといけないのですが、ファイルはエディターで普通に開けない大きさなので、面倒ですが読み込むスクリプトを書くしかありません。
コマンドラインでエンコーディングを確認してみると、charset=iso-8859-1が出てきます。
![]()
そのエンコーディングを指定してファイルを開いて最初の50行を出力させてみると、文字化け状態で出力されます。
max_line = 50
def get_next_line(f):
for line in f:
yield line
counter = 0
f = open("corpora00", encoding="iso-8859-1")
for line in get_next_line(f):
if counter > max_line:
break
counter += 1
print(line)
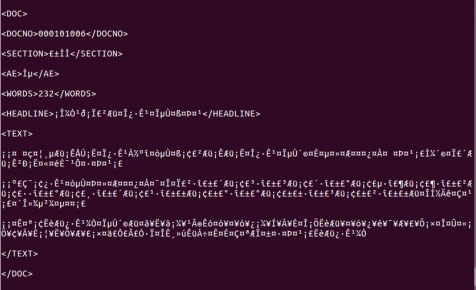
ローマ字しか適当に見えなくて困りますね。UTF-8でファイルを読み込んでみると、ファイルがダメな文字があるというエラーが発生します。エラーを無視しながらの読み込みはまた読める出力ではないです。どういうデコードを使えばいいかなと悩んでいました。
日本語の文字コードを詳しく調べて、一つ一つを試してみると、文字化けが直りました!
EUC-JP が手がかりになりました。
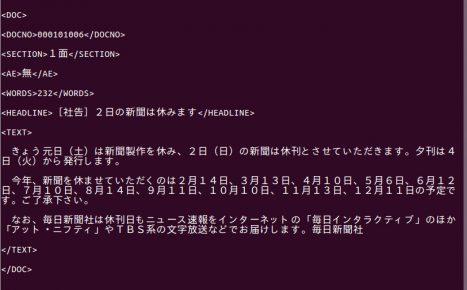
これで文章を読むことができるようになりました。実験が続けられます!





